
AI 助手也开始分“快慢班”了?深度求索的最新动作证监会允许的配资公司,揭开了大模型服务分层的一角。
4 月 8 日,深度求索(DeepSeek)在产品端上线了“专家模式”,与原有的“快速模式”并列。更新后,用户在网页输入框上方能看到两个图标:闪电代表“快速模式”,钻石则对应“专家模式”,两者定位截然不同。
快速模式追求即时响应,满足日常对话。它支持图片和文件中的文字识别(基于 OCR 技术),最多可处理 50 个文件,知识更新至 2025 年 5 月,风格直接简洁,旨在以最低等待成本解决普遍问题。
专家模式则被定位为处理复杂任务的专用通道。它擅长深度思考和复杂求解,可搭配联网搜索。但为确保算力集中于推理,当前版本暂不支持文件上传,知识库截止于 2025 年 5 月和快速模式一致,且在高峰时段可能需要排队。
使用过程中,专家模式响应会出现卡顿或者服务器繁忙的情况。
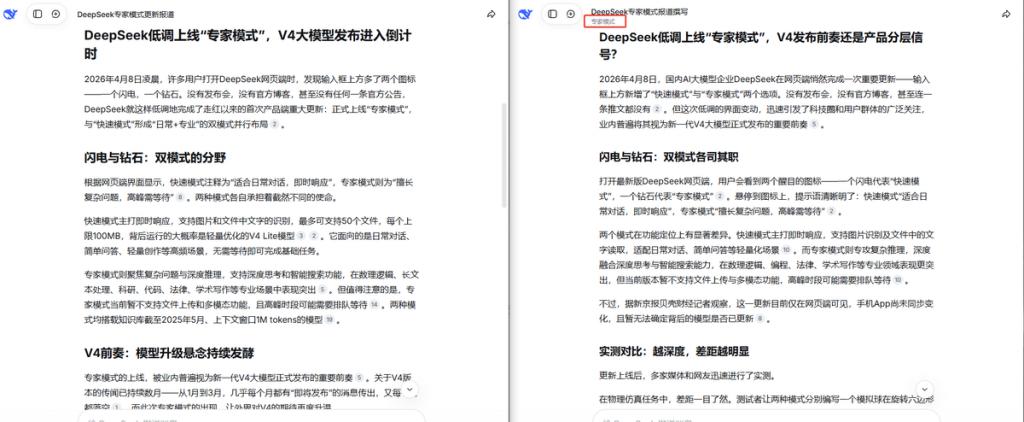
实测了一下,让两种模式分别写一篇专家模式的新闻报道,专家模式内容结构更为合理,可读性更强。
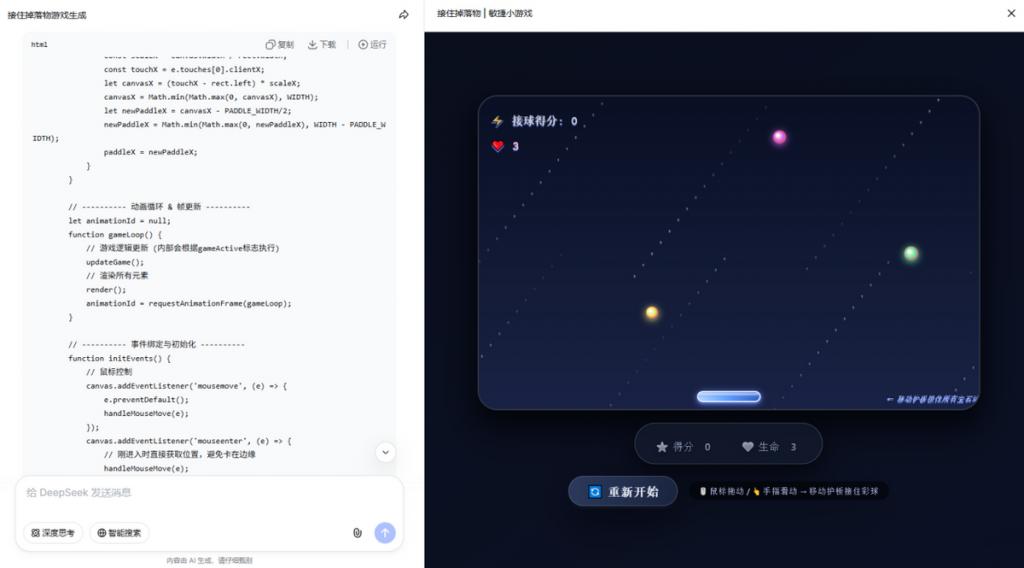
若是让它生成一个简单游戏画面,两者出来的框架及画面效果差异不大,反而专家模式的游戏体验难度较为不合理。
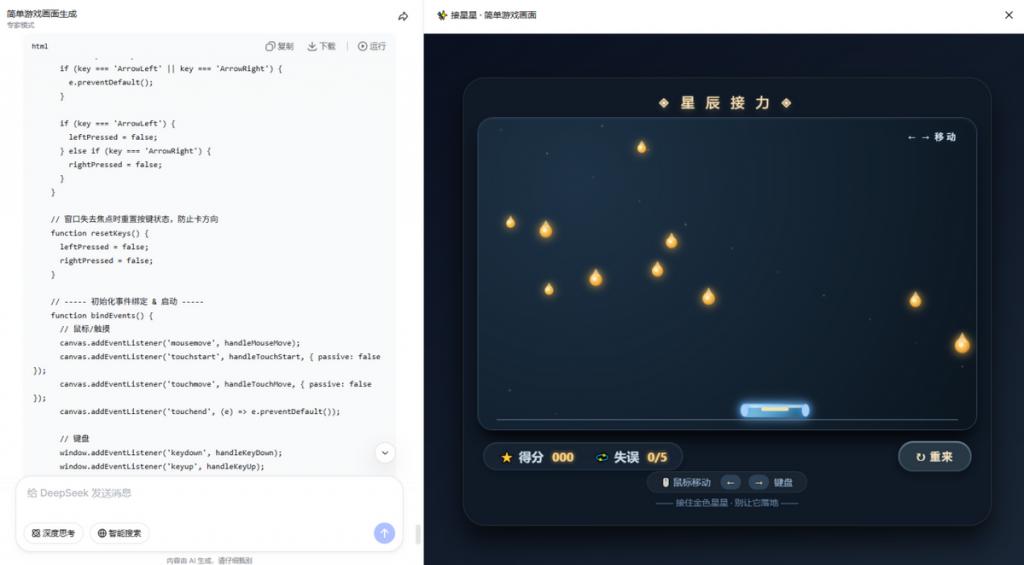
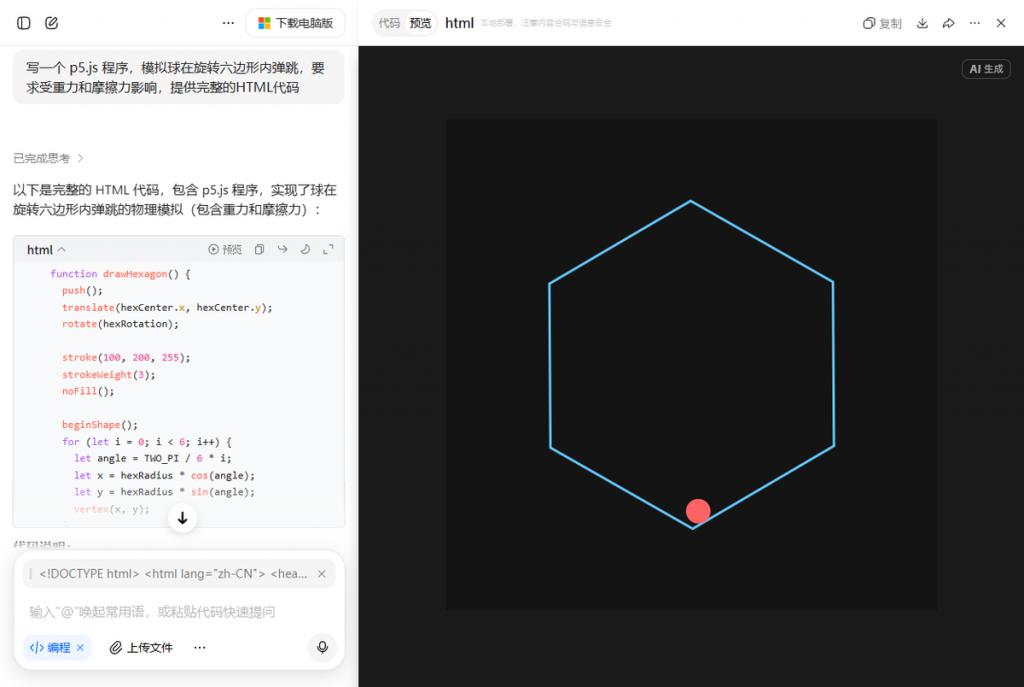
很多网友第一时间也做了测试比较,测试者让两种模式分别编写一个模拟球在旋转六边形内弹跳的 p5.js 程序,要求球体运动受重力和摩擦力影响。结果显示,专家模式给出的程序运行结果更符合物理直觉,落点精准,弹跳轨迹真实;而快速模式的结果则明显逊色不少。


分析认为,物理仿真对数学推理能力要求极高,弱一点的模型容易出现“看起来像物理但实际上不对”的情况,专家模式在此类场景中的优势是实打实的能力差异。
这种差异,直接体现了两种模式背后资源调度的不同优先级。
模式差异的根源,在于底层推理策略与架构优化方向不同。专家模式深度适配 DeepSeek 自研的混合专家模型(MoE)架构,最大化释放模型的深度推理能力,此次更新也被业内普遍视为下一代旗舰模型 V4 发布前的重要预演。
这种架构通过一个门控网络,为每个输入动态选择一小部分专精于不同任务(如语法分析、代码生成)的“专家”子网络进行计算。其精妙之处在于,模型能保持庞大参数总量(如 DeepSeek-V3 的 6710 亿参数),却仅激活一小部分(如 370 亿)来处理特定任务,从而在保持强大能力的同时,大幅提升计算效率。快速模式则可能基于更轻量化或经过不同优化的版本,优先保障响应速度与并发能力。
行业分析认为,双模式设计是平衡高昂算力与多元需求的必然选择。将计算密集型任务导向专家模式,日常对话交由快速模式处理,是一种精细化的资源分配策略。这既能为专业场景提供强大能力,又能以较低成本维持海量用户的日常体验。
下一代旗舰模型 V4 将在多模态能力上实现突破。不同于当前通过 OCR 间接处理图像,V4 据称采用原生多模态架构,能真正同时理解、处理并生成文本、图像乃至音频,实现“一次输入,全模态输出”。还有 V4 旨在突破现有模型“对话关闭即遗忘”的限制,通过创新记忆架构,使 AI 能像人类助手一样记住历史交互,自主归纳用户习惯。通过 MoE 架构演进、更智能的稀疏注意力机制,以及深度适配国产算力芯片,DeepSeek 致力于在提升性能的同时大幅降低训练与推理成本。未来的模型将更擅长自主规划、调用工具并完成复杂工作流。
因此有行业认为,专家模式对深度思考的侧重,正是在为此铺路。另外,多次被提及的 V4 的多模态能力,在此次更新中一个重要的“ Vision Mode ”并未上线。
值得一提,豆包专家模式 2 月 14 日上线,全能深度智能体,偏综合办公 / 多模态 / 工具链,强在图文、文档、图表、中文创作、工具内化。虽然都叫“专家模式”,但两者定位、技术路线、能力长板、使用体验差异非常大。
同样的实测,用豆包编写的模拟球在旋转六边形内弹跳的 p5.js 程序,效果及界面内容较为简单。
当 AI 开始为你“思考”得更深,我们准备好与之长期协作了吗?
来源:星河商业观察 证监会允许的配资公司
嘉股配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯
